










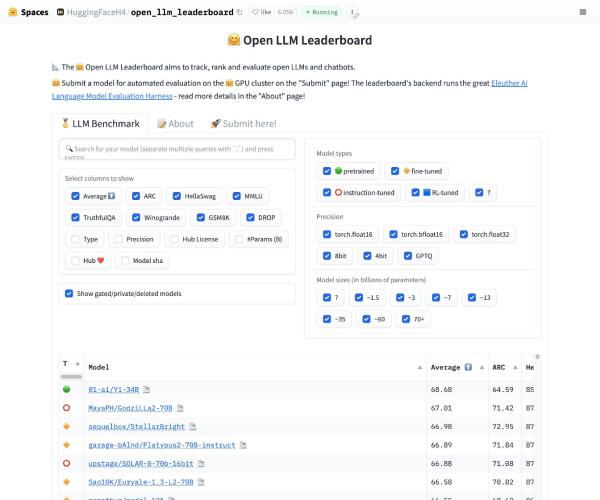
Open LLM Leaderboard 是最大的大模型和数据集社区 HuggingFace 推出的开源大模型排行榜单,基于 Eleuther AI Language Model Evaluation Harness(Eleuther AI语言模型评估框架)封装。
由于社区在发布了大量的大型语言模型(LLM)和聊天机器人之后,往往伴随着对其性能的夸大宣传,很难过滤出开源社区取得的真正进展以及目前的最先进模型。因此,Hugging Face 使用 Eleuther AI语言模型评估框架对模型进行四个关键基准测试评估。这是一个统一的框架,用于在大量不同的评估任务上测试生成式语言模型。
Open LLM Leaderboard 的评估基准
- AI2 推理挑战(25-shot):一组小学科学问题
- HellaSwag(10-shot):一个测试常识推理的任务,对人类来说很容易(大约95%),但对SOTA模型来说具有挑战性。
- MMLU(5-shot)- 用于测量文本模型的多任务准确性。测试涵盖57个任务,包括基本数学、美国历史、计算机科学、法律等等。
- TruthfulQA(0-shot)- 用于测量模型复制在在线常见虚假信息中的倾向性。
数据统计
相关导航

666ChatGPT资源导航,集AI问答网址、资源、资讯于一体,涵盖百度文心一言,OPEN AI ChatGPT,通义千问,腾讯混元,讯飞星火等语言模型,助力于办公 ,写作效率提升,释放AI时代生产力!

